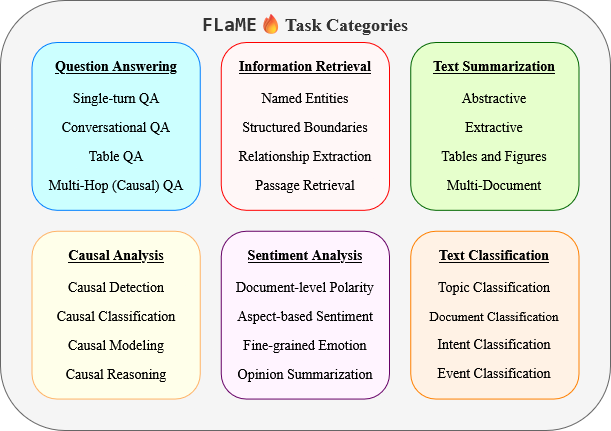
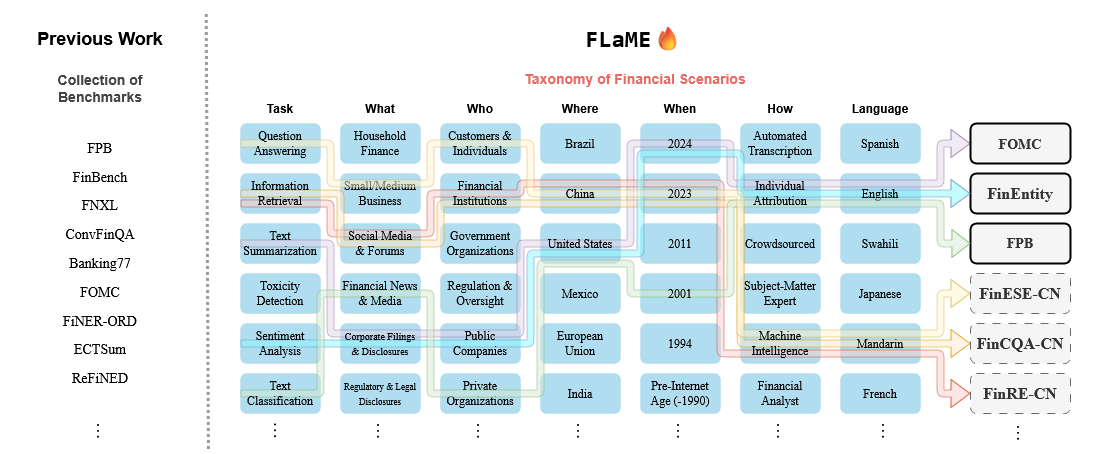
To strengthen the robustness and adaptability of our framework, we advocate for open collaboration within the research community
and propose the following future directions to expand its capabilities:
🌍 Multilingual Expansion
Extending benchmarks beyond English to include multilingual financial datasets and evaluations.
🧠 Few-Shot & Chain-of-Thought
Investigating in-context learning techniques such as few-shot, chain-of-thought, and retrieval-augmented generation (RAG).
⚙️ Domain-Adaptive Training
Evaluating fine-tuning strategies to enhance model understanding of financial-specific terminology and reasoning.
📊 Expanded Dataset Coverage
Curating datasets from underrepresented financial sectors such as insurance, derivatives, and central banking.
⚖️ Efficiency & Cost Benchmarking
Developing detailed trade-off analyses between accuracy, latency, and cost to optimize real-world usability.
📈 Advanced Evaluation Metrics
Moving beyond traditional accuracy metrics by incorporating trustworthiness, robustness, and interpretability measures.
These improvements will enable more accurate and fair comparisons of financial language models,
fostering greater transparency, reproducibility, and real-world applicability.